
キュー
キューはFIFO(First In, First Out)のデータ構造で、
入れた順番で出てくる箱みたいなものです。
これをC言語で簡単に使ってみましょう。
C言語でのキューの実装の一例
まず以下のように、配列1つと関数2つを用意します。
- 箱となる配列Q
- Qに要素を追加する関数enqueue
- Qから要素を取り出す関数dequeue
こんな感じです。
#include <stdio.h>
#define MAX_QUEUE_NUM 50
int head=0, tail=0;
void enqueue(int *Q, int a);
int dequeue(int *Q);
int main(void){
int Q[MAX_QUEUE_NUM];
return 0;
}
void enqueue(int *Q, int a){
Q[tail] = a;
tail++;
if(tail == MAX_QUEUE_NUM) tail = 0;
if(tail == head){
printf("error: enqueue overflow\n");
exit(1);
}
}
int dequeue(int *Q){
int a;
if(head == tail){
printf("error: dequeue underflow\n");
exit(1);
}else{
a = Q[head];
head++;
if(head == MAX_QUEUE_NUM) head = 0;
}
return a;
}1次元配列によるキューの構造は以下のようになっています。
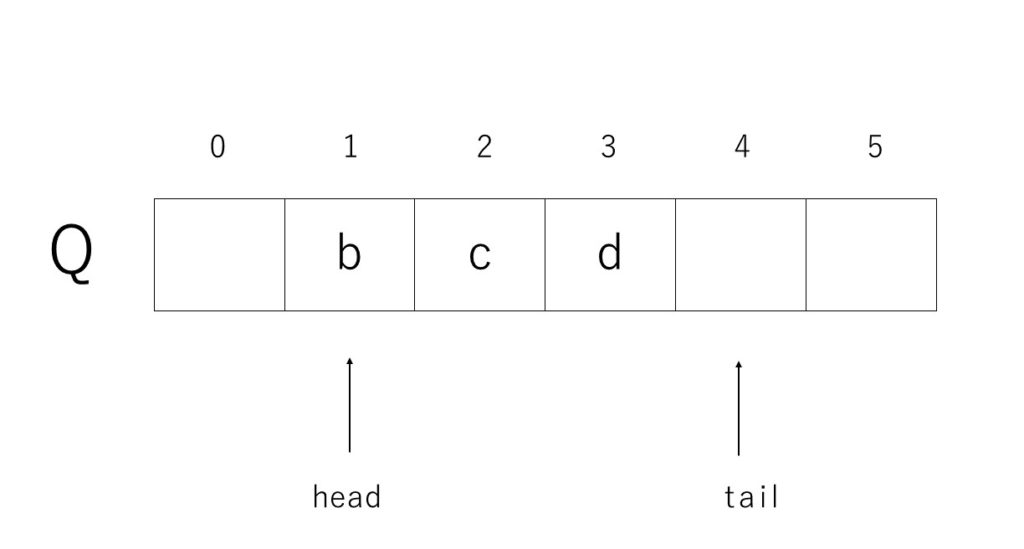
headとtailの初期値は0です。
enqueueではtailの位置に要素を入れた後tailの値に1を足します。
dequeueではheadの位置の要素を返り値用に変数aなどに入れておき、headの値に1を足した後、aを返します。
また、キューが空であるときはhead == tailなので、キューが空になるまで繰り返したい時はwhile(head != tail)と書けばよいです。
これは例えば幅優先探索などに使うことができます。
enqueueとdequeueのエラー処理
要素を追加するenqueueの操作内でhead == tailとなったら、tailが一周してきているということなので、これはQのサイズが足りていないことを意味します。この場合にはエラーを表示するような処理が必要です。
このエラーがでたらキューのサイズをもっと大きくとりなおせばよいです。
また、要素を取り出すdequeueを実行したときにすでにhead == tailとなっていた場合、「ないものを取り出そうとしている」という意味なので、アルゴリズムの設計ミスが考えられます。この場合もエラーを表示する処理が必要です。
このエラーがでてしまったらアルゴリズム自体にどこかミスがないか探して直す必要があります。
スタック
スタックはLIFO(Last In, First Out)のデータ構造で、
後に入れたものほど先にでてくる、あるいは先に入れたものほど後からでてくる箱みたいなものです。
入れるときは下から積み上げて、取り出すときは上からもっていくような順番になります。
C言語でのスタックの実装の一例
これをC言語で簡単に実装するとこんな感じです。
- 箱となる配列S
- Sに要素を追加する関数push
- Sから要素を取り出す関数pop
#include <stdio.h>
#define MAX_STACK_NUM 50
int top=-1;
void push(int *S, int a);
int pop(int *S);
int main(void){
int S[MAX_STACK_NUM];
return 0;
}
void push(int *S, int a){
top++;
if(top == MAX_STACK_NUM){
printf("error: push overflow\n");
exit(1);
}else{
S[top] = a;
}
}
int pop(int *S){
int a;
if(top == -1){
printf("error: pop underflow\n");
exit(1);
}else{
a = S[top];
top--;
return a;
}
}1次元配列によるスタックの構造は以下のようになっています。
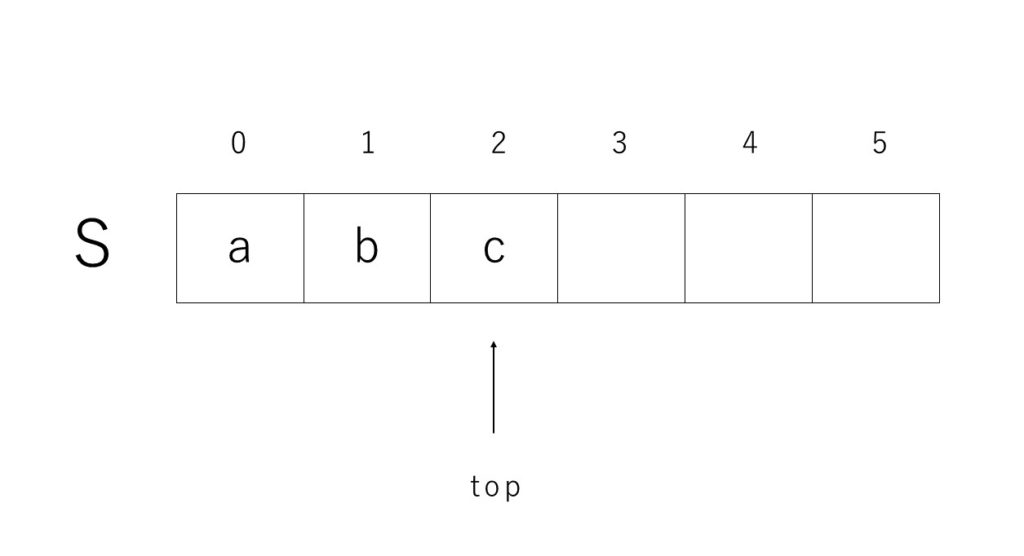
topの初期値は-1です。
pushではtopの値を1足してからその位置に要素を入れます。
popではtopの位置の要素を返り値用に変数aなどに入れておき、topの値を1つ減らした後、aを返します。
また、スタックが空であるときはtop==-1なので、キューが空になるまで繰り返したい時はwhile(top != -1)と書けばよいです
これは例えば深さ優先探索などに使うことができます。
pushとpopのエラー処理
要素を追加するpushの操作において、popの値がスタックのサイズを超えてしまった場合はスタックのサイズが足りていないので、エラーを知らせる表示をします。
このエラーがでたらスタックのサイズをもっと大きくとりなおせばよいです。
また、要素を取り出すpopの操作において、要素を取り出す前にすでにtop==-1となっていた場合は、「ないものを取り出そうとしている」という意味なので、アルゴリズムの設計ミスが考えられます。この場合もエラーを知らせる表示をします。
このエラーがでてしまったらアルゴリズム自体にどこかミスがないか探して直す必要があります。
キューやスタックを用いた例として隣接行列に対する幅優先探索(BFS)と深さ優先探索(DFS)をC言語で実装した例を作りました。
おまけで再帰処理を用いた深さ優先探索も入っています。

